What is Data?
Data is a collection of information. gathered by observation, questioning or measurement.
In computing, data is information that has been translated into a form that is efficient for movement or processing. Relative to today's computers and transmission media, data is information converted into binary digital form. Raw data is a term used to describe data in its most basic digital format.
What is data processing?
Data processing occurs when data is collected and translated into usable information. It is important for data processing to be done correctly as not to negatively affect the end product, or data output.
Data processing starts with data in its raw form and converts it into a more readable format (graphs, documents, etc.), giving it the form and context necessary to be interpreted by computers and utilized by employees throughout an organization.
There are six stages of data processing
1. Data collection
Collecting data is the first step in data processing. Data is pulled from available sources. It is important that the data sources available are trustworthy and well-built so the data collected (and later used as information) is of the highest possible quality.
2. Data preparation
Once the data is collected, it then enters the data preparation stage. Data preparation, often referred to as “pre-processing” is the stage at which raw data is cleaned up and organized for the following stage of data processing. During preparation, raw data is diligently checked for any errors. The purpose of this step is to eliminate bad data (redundant, incomplete, or incorrect data) and begin to create high-quality data for the best business intelligence.
3. Data input
The clean data is then entered into its destination, usually using a data entry form. Data input is the first stage in which raw data begins to take the form of usable information.
4. Processing
During this stage, the data inputted to the computer in the previous stage is actually processed for interpretation. Processing is done using machine learning algorithms, though the process itself may vary slightly depending on the source of data being processed and its intended use (examining advertising patterns, medical diagnosis from connected devices, determining customer needs, etc.).
5. Data output/interpretation
The output/interpretation stage is the stage at which data is finally usable to end users. It is translated, readable, and often in the form of graphs, videos, images, plain text, etc.). Members of the company or institution can now begin to self-serve the data for their own data analytics projects.
6. Data storage
The final stage of data processing is storage. After all of the data is processed, it is then stored for future use. While some information may be put to use immediately, much of it will serve a purpose later on. When data is properly stored, it can be quickly and easily accessed by members of the organization when needed.
What is File?
File is a collection of records related to each other. The file size is limited by the size of memory and storage medium.
There are two important features of file:
1. File Activity
2. File Volatility
File activity specifies percent of actual records which proceed in a single run.
File volatility addresses the properties of record changes.
File Organization
A file is a sequence of records. File organization refers to physical layout or a structureof record occurrences in a file. File organization determines the way records are stored and accessed. File organization ensures that records are available for processing. It is used to determine an efficient file organization for each base relation. For example, if we want to retrieve employee records in alphabetical order of name. Sorting the file by employee name is a good file organization. However, if we want to retrieve all employees whose marks are in a certain range, a file is ordered by employee name would not be a good file organization.
Types of File Organization
There are three types of organizing the file:
1. Sequential access file organization
2. Direct access file organization
3. Indexed sequential access file organization
1. Sequential access file organization
Storing and sorting in contiguous block within files on tape or disk is called as sequential access file organization.
In sequential access file organization, all records are stored in a sequential order. The records are arranged in the ascending or descending order of a key field.
Sequential file search starts from the beginning of the file and the records can be added at the end of the file.
In sequential file, it is not possible to add a record in the middle of the file without rewriting the file.
Advantages of sequential file
It is simple to program and easy to design.
Sequential file makes the best use of storage space.
Disadvantages of sequential file
Sequential file is time consuming process.
It has high data redundancy.
Random searching is not possible.
What is the need of sorting a file
Sorting is the process of arranging data into meaningful order so that we can analyze it more effectively. Arranging records in a particular sequence is a common requirement in data processing. Such record sequencing can be accomplished using sort or merge operations. The sort operation accepts unsequenced input and produces output in a specified sequence.
Advantage of Sorting
1) Data gets arranged in a Systematic Representation
2) Better Visualization and Understanding of Data
3) Analyzing of huge amount of data becomes easier by Sorting
4) Reduces time consumption in Research and Analysis Works
Write short notes on Natural Merge
Natural Merge:
Merge sort is one of the most efficient sorting algorithms. It works on the principle of Divide and Conquer. Merge sort repeatedly breaks down a list into several sublists until each sublist consists of a single element and merging those sublists in a manner that results into a sorted list.
Natural Merge is a improved version of bottom-up mergesort. It finds and merges pairs of subsequence that are already ordered. So Natural Merge Sort is an optimization of Merge Sort, it identifies pre-sorted areas (“runs”) in the input data and merges them. This prevents the unnecessary further dividing and merging of presorted subsequences. Input elements sorted entirely in ascending order are therefore sorted in O(n).
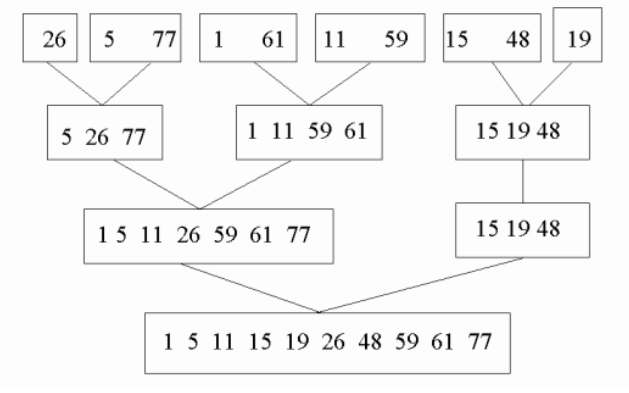 Example of Merge Sort
Example of Merge Sort
Write short notes on Balanced Merge
A merge sort, sorts a data stream using repeated merges. It distributes the input into k streams by repeatedly reading a block of input that fits in memory, called a run, sorting it, then writing it to the next stream. It then repeatedly merges the k streams and puts each merged run into one of j output streams until there is a single sorted output.
A balanced k-way merge sort, sorts a data stream using repeated merges. It distributes the input into two streams by repeatedly reading a block of input that fits in memory, a run, sorting it, then writing it to the next stream. It then repeatedly merges the two streams and puts each merged run into one of two output streams until there is a single sorted output.
2. Direct access file organization
Direct access file is also known as random access or relative file organization.
In direct access file, all records are stored in direct access storage device (DASD), such as hard disk. The records are randomly placed throughout the file.
The records does not need to be in sequence because they are updated directly and rewritten back in the same location.
This file organization is useful for immediate access to large amount of information. It is used in accessing large databases.
It is also called as hashing.
Advantages of direct access file organization
Direct access file helps in online transaction processing system (OLTP) like online railway reservation system.
In direct access file, sorting of the records are not required.
It accesses the desired records immediately.
It updates several files quickly.
It has better control over record allocation.
Disadvantages of direct access file organization
Direct access file does not provide back up facility.
It is expensive.
It has less storage space as compared to sequential file.
What is Indexing?
Indexing is a technique for improving database performance by reducing the number of disk accesses necessary when a query is run. An index is a form of data structure. It’s used to swiftly identify and access data and information present in a database table. In database systems, indexing is comparable to indexing in books. The indexing attributes are used to define the indexing.
Index structure:

Indexes can be created using some database columns.
The first column of the database is the search key that contains a copy of the primary key or candidate key of the table. The values of the primary key are stored in sorted order so that the corresponding data can be accessed easily.
The second column of the database is the data reference. It contains a set of pointers holding the address of the disk block where the value of the particular key can be found.
Methods of Indexing:
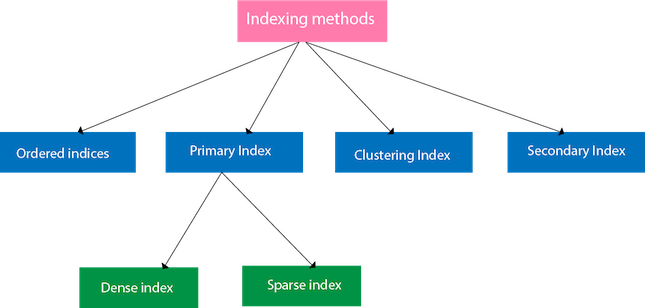
Differentiate between Dense and Non Dense Index.
Dense index: In a dense index, an index entry appears for every search-key value in the file. In a dense clustering index, the index record contains the search-key value and a pointer to the first data record with that search-key value. The rest of the records with the same search-key value would be stored sequentially after the first record, since, because the index is a clustering one, records are sorted on the same search key. In a dense nonclustering index, the index must store a list of pointers to all records with the same search-key value.

Sparse index: In a sparse index, an index entry appears for only some of the search-key values. Sparse indices can be used only if the relation is stored in sorted order of the search key, that is if the index is a clustering index. As is true in dense indices, each index entry contains a search-key value and a pointer to the first data record with that search-key value. To locate a record, we find the index entry with the largest search-key value that is less than or equal to the search-key value for which we are looking. We start at the record pointed to by that index entry, and follow the pointers in the file until we find the desired record.
What is ISAM?
ISAM (Indexed Sequential Access Method) is a file management system developed at IBM that allows records to be accessed either sequentially (in the order they were entered) or randomly (with an index). Each index defines a different ordering of the records.
For Example: An employee database may have several indexes, based on the information being sought. For example, a name index may order employees alphabetically by last name, while a department index may order employees by their department. A key is specified in each index. For an alphabetical index of employee names, the last name field would be the key.
ISAM was developed prior to VSAM (Virtual Storage Access Method) and relational databases. ISAM is now obsolete.
3. Indexed sequential access file organization
Indexed sequential access file combines both sequential file and direct access file organization.
In indexed sequential access file, records are stored randomly on a direct access device such as magnetic disk by a primary key.
This file have multiple keys. These keys can be alphanumeric in which the records are ordered is called primary key.
The data can be access either sequentially or randomly using the index. The index is stored in a file and read into memory when the file is opened.
Advantages of Indexed sequential access file organization
In indexed sequential access file, sequential file and random file access is possible.
It accesses the records very fast if the index table is properly organized.
The records can be inserted in the middle of the file.
It provides quick access for sequential and direct processing.
It reduces the degree of the sequential search.
Disadvantages of Indexed sequential access file organization
Indexed sequential access file requires unique keys and periodic reorganization.
Indexed sequential access file takes longer time to search the index for the data access or retrieval.
It requires more storage space.
It is expensive because it requires special software.
It is less efficient in the use of storage space as compared to other file organizations.
What is VSAM?
Virtual storage access method (VSAM) is a file storage access method used in IBM mainframes. VSAM is an expanded version of indexed sequential access method (ISAM), which was the file access method used previously by IBM.
VSAM enables the organization of records in physical or logical sequences. Files can also be indexed by record number. VSAM helps enterprises by providing quick access to data by the use of the inverted index. The records in VSAM can be either variable or fixed length.
VSAM consists of four major types of data sets (a file is represented by data set by IBM), these include:
Key-sequenced data set (KSDS)
Relative record data set (RRDS)
Entry-sequenced data set (ESDS)
Linear data set (LDS)
KSDS, RRDS and ESDS contain records while LDS consists of page sequences.
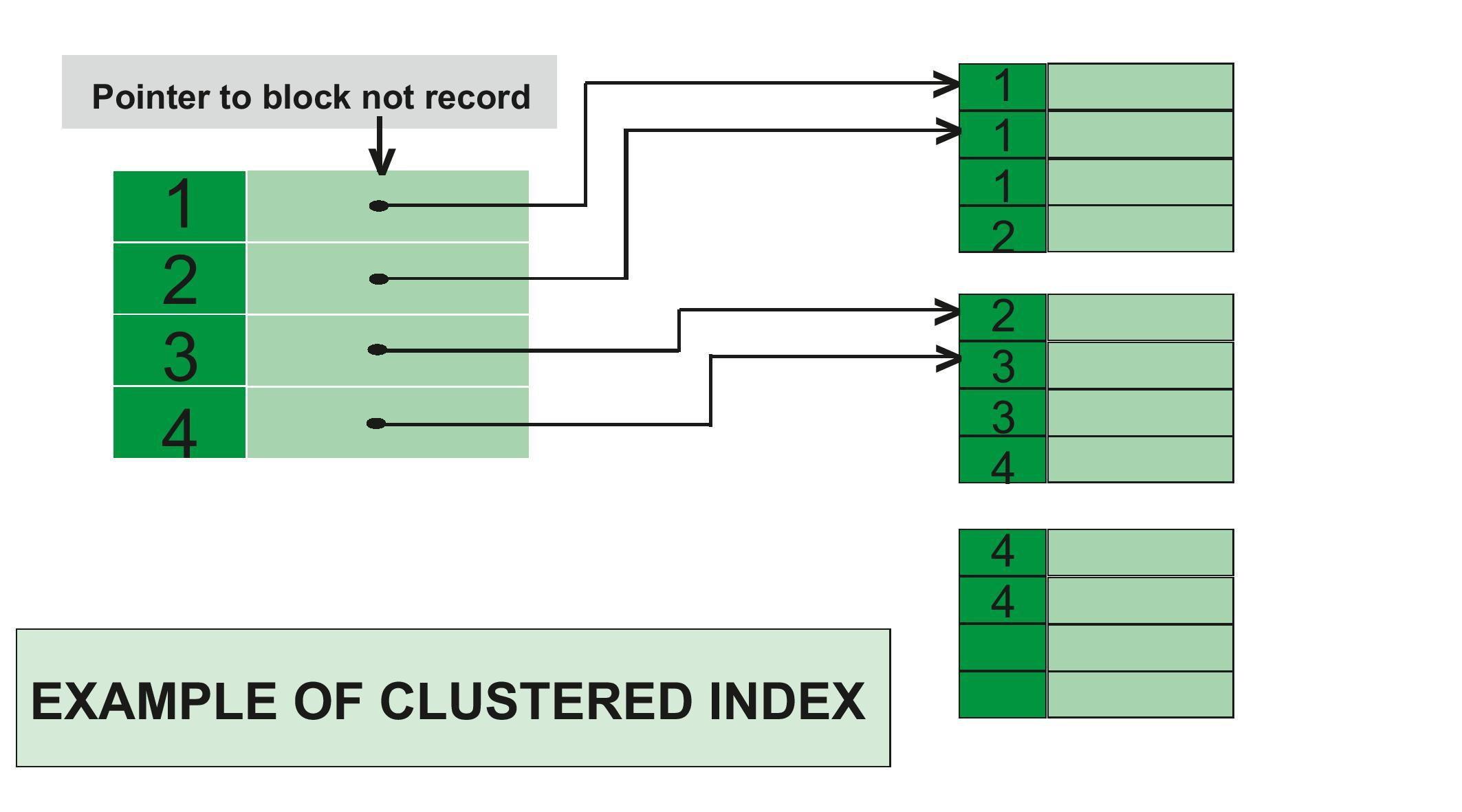
What is Clustering Index?
A clustering index determines how rows are physically ordered (clustered) in a table space. Clustering indexes provide significant performance advantages in some operations, particularly those that involve many records. Examples of operations that benefit from clustering indexes include grouping operations, ordering operations, and comparisons other than equal.
Any index, except for an expression-based index or an XML index, can be a clustering index. We can define only one clustering index on a table.
We can define a clustering index on a partitioned table space or on a segmented table space. On a partitioned table space, a clustering index can be a partitioning index or a secondary index. If a clustering index on a partitioned table is not a partitioning index, the rows are ordered in cluster sequence within each data partition instead of spanning partitions.
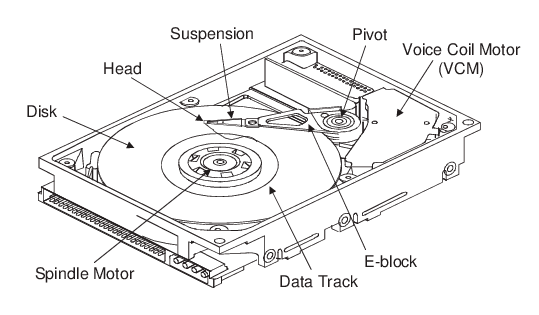
Computer Storage Devics
Timeline of Computer Storage Devics
Mechanical Components of a typical Hard Disk Drive
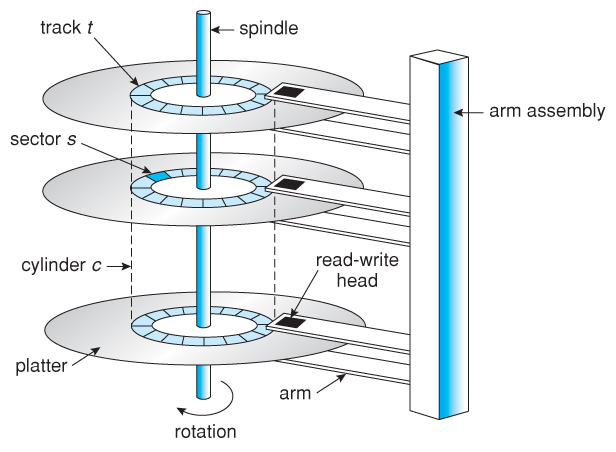
Moving-head Disk Mechanism
File Storage Concepts
The records of a file must be allocated to disk blocks because a block is a unit of data transfer between disk and memory.
The division of a track (on storage medium) into equal sized disk blocks is set by the operating system during disk formatting.
The hardware address of a block comprises a surface number, track number and block number.
Buffer – a contiguous reserved area in main storage that holds one block-has also an address. For a read command, the block from disk is copied into the buffer, whereas for a write command the contents of the buffer are copied into the disk block.
Sometimes several contiguous blocks, called a cluster, may be transferred as a unit. In such cases buffer size is adjusted to cluster size. When the block size is larger than the record size, each block will contain numerous records, while there can be files with large records that cannot fit in one block. In the latter case the records can span more than one block.
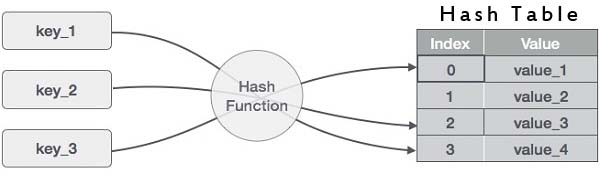
What is hashing and why it is used?
Hashing is the process of transforming any given key or a string of characters into another value. This is usually represented by a shorter, fixed-length value or key that represents and makes it easier to find or employ the original string. Hashing is used to index and retrieve information from a database because it helps accelerate the process; it is much easier to find an item using its shorter hashed key than its original value.
The most popular use for hashing is the implementation of hash tables. A hash table is a special collection that is used to store items in a key-value pair. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
Use of Hash Function
Generation of Hash Table Structure
Double Hashing:
Double hashing is a technique used for avoiding collisions in hash tables. A collision occurs when two keys are hashed to the same index in a hash table. Collisions are a problem because every slot in a hash table is supposed to store a single element. Double hashing uses the idea of applying a second hash function to key when a collision occurs.
Advantages of Double hashing:
The advantage of Double hashing is that it is one of the best form of probing, producing a uniform distribution of records throughout a hash table.
This technique does not yield any clusters.
It is one of effective method for resolving collisions.
Double hashing can be done using:
(hash1(key) + i * hash2(key)) % TABLE_SIZE
Here hash1() and hash2() are hash functions and TABLE_SIZE is size of hash table.
(We repeat by increasing i when collision occurs)
First hash function is typically hash1(key) = key % TABLE_SIZE
A popular second hash function is : hash2(key) = PRIME – (key % PRIME) where PRIME is a prime smaller than the TABLE_SIZE.
A good second Hash function is:
It must never evaluate to zero
Must make sure that all cells can be probed
What is meant by bucket addressing.
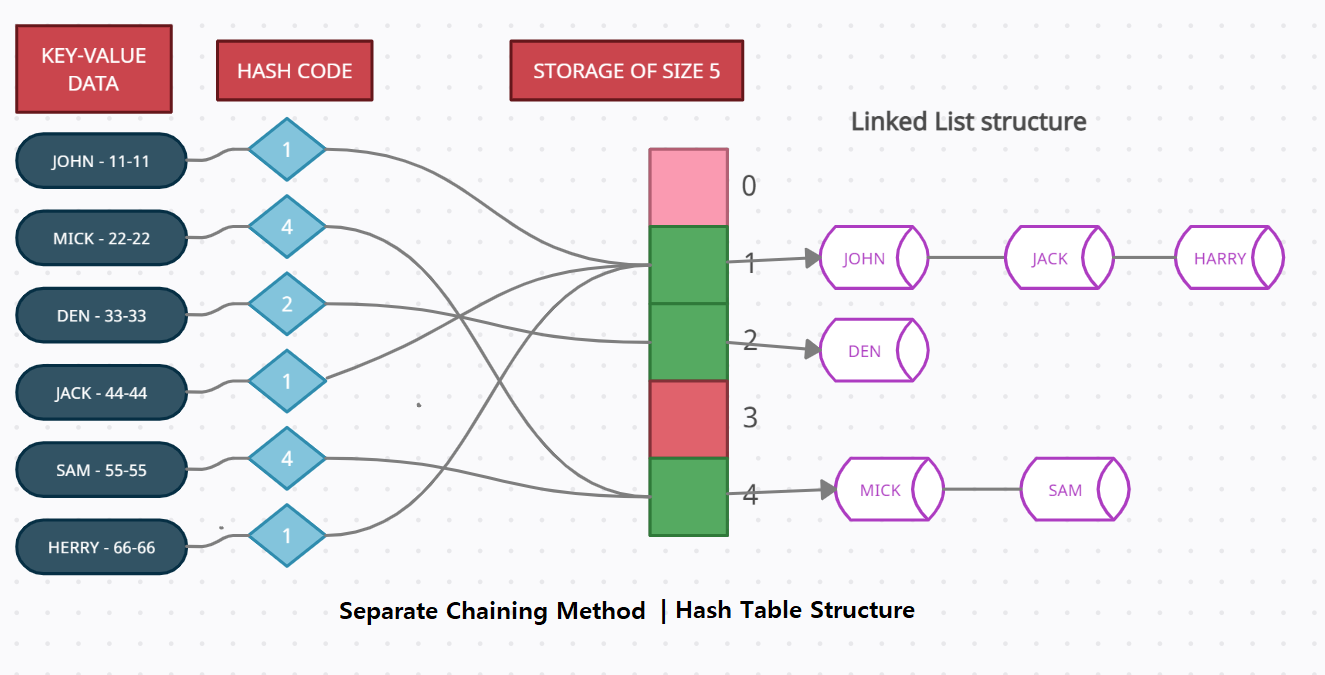
One solution to the hash collision problem is to store colliding elements in the same position in table by introducing a bucket with each hash address. A bucket is a block of memory space, which is large enough to store multiple itmes, the mapping of the hash address within each Bucket is called as bucket addressing.
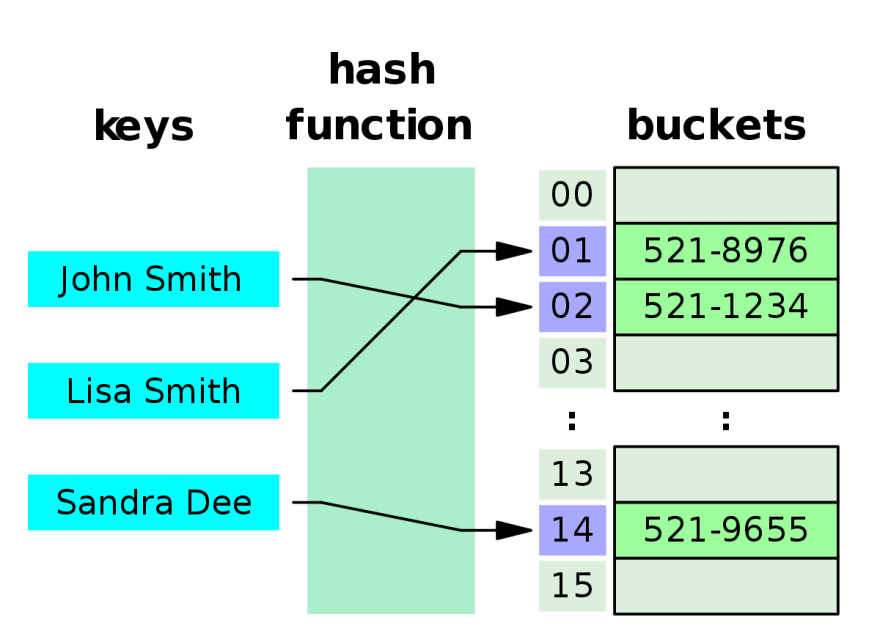
Hash buckets are used to apportion data items for sorting or lookup purposes. The aim of this work is to weaken the linked lists so that searching for a specific item can be accessed within a shorter timeframe. A hash table that uses buckets is actually a combination of an array and a linked list. Each element in the array [the hash table] is a header for a linked list. All elements that hash into the same location will be stored in the list.
When searching for a record, the first step is to hash the key to determine which bucket should contain the record. The records in this bucket are then searched. If the desired key value is not found and the bucket still has free slots, then the search is complete. If the bucket is full, then it is possible that the desired record is stored in the overflow bucket. In this case, the overflow bucket must be searched until the record is found or all records in the overflow bucket have been checked. If many records are in the overflow bucket, this will be an expensive process.
What is a B-tree?
A B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
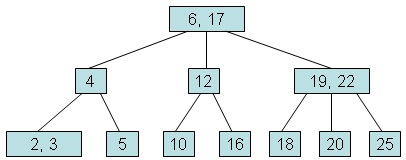 Example of B-tree
Example of B-tree
Rules:
The B-tree can have any order greater than 2.
A B-tree node can contain more than one key values whereas a BST node contains only one. There are lower and upper bounds on the number of keys a node can contain. These bounds can be expressed in terms of a fixed integer T>=2 called the minimum degree of the B-tree.
Every node other than the root must have at least T-1 keys. Every internal node other than the root must have at least T children.
Every node can contain at most 2T-1 keys. Therefore, an internal node can have at most 2T children. We say that the node is full if it contains exactly 2T-1 keys.
Reason for using B-Tree
Here, are reasons of using B-Tree
1) Reduces the number of reads made on the disk
2) B Trees can be easily optimized to adjust its size (that is the number of child nodes) according to the disk size
3) It is a specially designed technique for handling a bulky amount of data.
4) It is a useful algorithm for databases and file systems.
5) B-Tree is a good choice to opt when it comes to reading and writing large blocks of data
Logarithmic time complexity log(n): Represented in Big O notation as O(log n), when an algorithm has O(log n) running time, it means that as the input size grows, the number of operations grows very slowly.
The order of a B-tree is that maximum. A Binary Search Tree, for example, has an order of 2. The degree of a node is the number of children it has. So every node of a B-tree has a degree greater than or equal to zero and less than or equal to the order of the B-tree.
What is a Key?
A key refers to an attribute/a set of attributes that help us identify a row (or tuple) uniquely in a table (or relation). A key is also used when we want to establish relationships between the different columns and tables of a relational database. The individual values present in a key are commonly referred to as key values. We use a key for defining various types of integrity constraints in a database. A table, on the other hand, represents a collection of the records of various events for any relation.
Keys are of seven broad types in DBMS:
1. Candidate Key
2. Primary Key
3. Foreign Key
4. Super Key
5. Alternate Key
6. Composite Key
7. Unique Key
Database Management System (DBMS):
A database management system (or DBMS) is a computerized data-keeping system. Users of the system are given facilities to perform several kinds of operations on such a system for either manging of the data in the database or the management of the database structure itself. DBMS allows users to define, create, maintain and control access to the database. DBMS makes it possible for end users to create, read, update and delete data in database. It is a layer between programs and data. Database Management Systems are categorized according to their data structures or types.
Types of Database Management System:
Hierarchical Database Systems
Network Database Systems
Object-Oriented Database Systems
Hierarchical database model resembles a tree structure, similar to a folder architecture in our computer system. The relationships between records are pre-defined in a one to one manner, between 'parent and child' nodes. They require the user to pass a hierarchy in order to access needed data. Due to limitations, such databases may be confined to specific uses.
Network database models also have a hierarchical structure. However, instead of using a single-parent tree hierarchy, this model supports many to many relationships, as child tables can have more than one parent.
In object-oriented databases, the information is represented as objects, with different types of relationships possible between two or more objects. Such databases use an object-oriented programming language for development.
Advantage of Database Management System:
Reducing Data Redundancy
The file based data management systems contained multiple files that were stored in many different locations in a system or even across multiple systems. Because of this, there were sometimes multiple copies of the same file which lead to data redundancy.
This is prevented in a database as there is a single database and any change in it is reflected immediately. Because of this, there is no chance of encountering duplicate data.
Sharing of Data
In a database, the users of the database can share the data among themselves. There are various levels of authorisation to access the data, and consequently the data can only be shared based on the correct authorisation protocols being followed.
Many remote users can also access the database simultaneously and share the data between themselves.
Data Integrity
Data integrity means that the data is accurate and consistent in the database. Data Integrity is very important as there are multiple databases in a DBMS. All of these databases contain data that is visible to multiple users. So it is necessary to ensure that the data is correct and consistent in all the databases and for all the users.
Data Security
Data Security is vital concept in a database. Only authorised users should be allowed to access the database and their identity should be authenticated using a username and password. Unauthorised users should not be allowed to access the database under any circumstances as it violates the integrity constraints.
Privacy
The privacy rule in a database means only the authorized users can access a database according to its privacy constraints. There are levels of database access and a user can only view the data he is allowed to. For example - In social networking sites, access constraints are different for different accounts a user may want to access.
Backup and Recovery
Database Management System automatically takes care of backup and recovery. The users don't need to backup data periodically because this is taken care of by the DBMS. Moreover, it also restores the database after a crash or system failure to its previous condition.
Data Consistency
Data consistency is ensured in a database because there is no data redundancy. All data appears consistently across the database and the data is same for all the users viewing the database. Moreover, any changes made to the database are immediately reflected to all the users and there is no data inconsistency.
Structure of DBMS:
The database system is divided into three components: Query Processor, Storage Manager, and Disk Storage. These are explained as following below.
Applications: – It can be considered as a user-friendly form where the user enters the requests. Here he simply enters the details that he needs and presses buttons to get the data.
End User: – They are the real users of the database. They can be developers, designers, administrators, or the actual users of the database.
DDL: – Data Definition Language (DDL) is a query fired to create database, schema, tables, mappings, etc in the database. These are the commands used to create objects like tables, indexes in the database for the first time. In other words, they create the structure of the database.
DDL Compiler: – This part of the database is responsible for processing the DDL commands.
DML Compiler: – DML compiler translates DML statements in a query language into a low-level instruction and the generated instruction can be understood by Query Evaluation Engine.
Query Optimizer: - The query optimizer is built-in database software that determines the most efficient method for a SQL statement to access requested data.
Stored Data Manager: - Stored Data Manager is a program that provides an interface between the data stored in the database and the queries received.
Data Files: – It has the real data stored in it. It can be stored as magnetic tapes, magnetic disks, or optical disks.
Compiled DML: - The DML complier converts the high level Queries into low level file access commands known as compiled DML.
Data Dictionary: – It contains all the information about the database. It is the dictionary of all the data items. It contains a description of all the tables, view, materialized views, constraints, indexes, triggers, etc.
Explain E-R Model in detail with suitable examples
ER model:
ER model stands for an Entity-Relationship model. ER Modeling is a graphical approach to database design. It is a high-level data model and is used to model the logical view of the system from data perspective and is used to define the Entities, their attributes and their relationship for a specified system. ER model helps to develop the conceptual design for the database. It also helps to develop a very simple and easy to design view of data. In ER modeling, the database structure is portrayed as a diagram called an entity-relationship diagram. The ER model defines the conceptual view of a database. It works around real-world entities and the associations among them.
According to the database system management system the entity is considered as a table and attributes are columns of a table. So the ER diagram shows the relationship among tables in the database. The entity is considered a real-world object which is stored physically in the database. The entities have attributes that help to uniquely identify the entity. The entity set can be considered as a collection of similar types of entities.
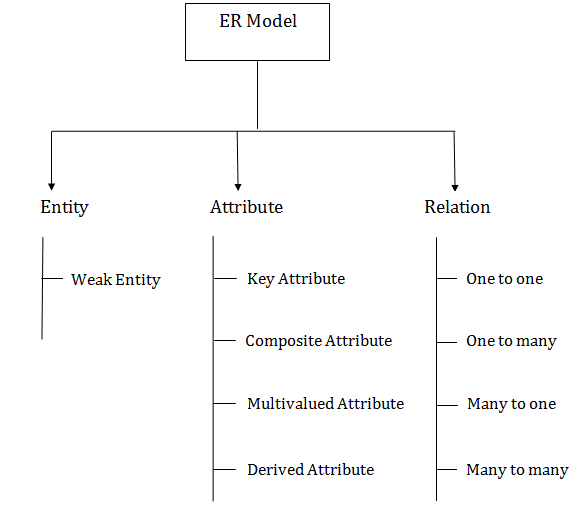
1. Entity:
An entity may be any object, class, person or place. In the ER diagram, an entity can be represented as rectangles.
2. Attribute
The attribute is used to describe the property of an entity. Eclipse is used to represent an attribute.
3. Relationship
A relationship is used to describe the relation between entities. Diamond or rhombus is used to represent the relationship.
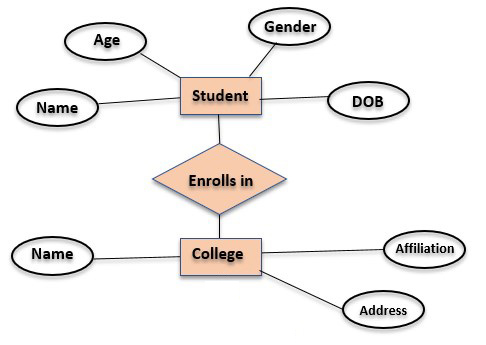
Example ER Model for Student College Admission System
What is Relational Model in DBMS
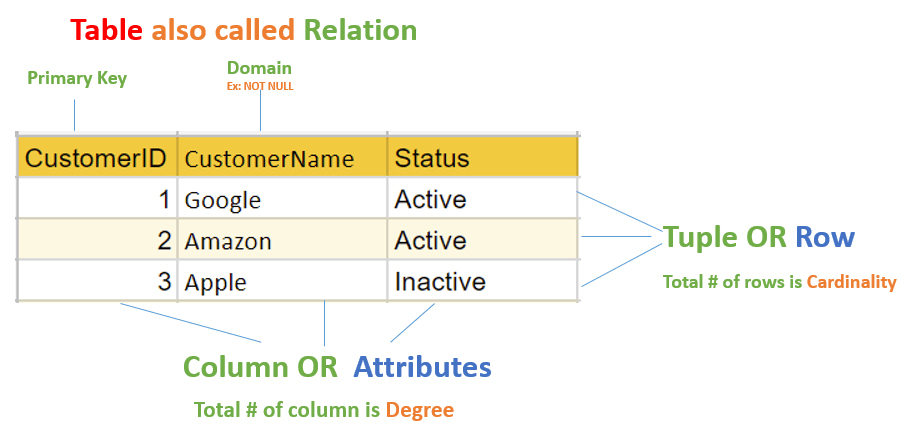
The relational model for database management is an approach to logically represent and manage the data stored in a database. In this model, the data is organized into a collection of two-dimensional inter-related tables, also known as relations. Each relation is a collection of columns and rows, where the column represents the attributes of an entity and the rows (or tuples) represents the records.
The use of tables to store the data provided a straightforward, efficient, and flexible way to store and access structured information. Because of this simplicity, this data model provides easy data sorting and data access. Hence, it is used widely around the world for data storage and processing.